Make sure you know what you can scrap and what you cannot by reading the platform’s official documents. Most of the platforms would have a “platform.robots.txt” page. Here is the one for YouTube: https://www.youtube.com/robots.txt. See Fig. 1 below.
Fig.1 robots.txt of YouTube
YouTube also has a very detailed official Data API document, where you can find the data you can scrape from this API in its Reference file. We will take a look at it together later.
If you plan to scrape a considerable amount of data using R, you should use the polite package to seek permission and take pauses in data requests. In this class, we only obtain a small amount of data, so we won’t use this package. But check out how to use politehere and here if you have a heavy data scraping task.
ATTENTION
In this class, I will demonstrate the codes for scrapping. If many of us run those codes at the same time, we are highly likely to get access denied. To avoid this issue, I will provide the scraped data. You can download it and load it in your Rstudio, and avoid of running any scraping related codes (I will note which are codes for scraping). With the provided scraped data, you can run other non-scraping codes for practice alongside the class. You can try the codes for scrapping after the class and scrape the videos of interest.
Download the scraped data here. And load the data with the following codes:
load("your directory/YT_scraped_Data.RData")
2 A simple example
Instead of writing our own API applications to access the YouTube data, we use two off-the-shelf R packages, tuber and vosonSML, which provide handy functions to quickly scrape video and user data.
Of course, since these two packages were written for the authors’ own interest, you may not find the YouTube data you want to use. In this case, you may want to write your own applications. You can find an awesome example of writing API calls using R here. For teaching purposes, we will use these two handy R packages.
#install.packages(c("vosonSML", "tuber", "httpuv")) library(vosonSML) # we use it for collecting comments datalibrary(tuber) # we use if for collecting video and channel attributes.
Warning: package 'tuber' was built under R version 4.3.3
library(tidyverse) # we use it for data wrangling
Warning: package 'tidyverse' was built under R version 4.3.3
Warning: package 'dplyr' was built under R version 4.3.3
Warning: package 'stringr' was built under R version 4.3.3
Warning: package 'lubridate' was built under R version 4.3.3
library(httpuv) # we use it for handling HTTP and WebSocket requests.
In the following, we use two YouTube videos to show a basic workflow for extracting video and channel information. These two videos were created by David Robinson and Julia Silge, who are data scientiests and the authors of Text Mining with R. They are also R educators who have been active in the weekly R social learning event TidyTuesday for years. Check it out if you want to practice and improve your R skills.
2.1 Gain access permission
In last class, we gained our autentication information, including API key, client ID, and client secret. We also used the following chunk to input those authentication information in the .Renviron file. Double check if you have the autentification information stored correctly. This is a practice of secure your authentication information. See more about the best practices of using APIs in R suggested by Chung-hong Chan.
Then a message would show in your console. Then put “1” in console, directing to a webpage requesting access to your account. Select yes and you should see an message saying the authentication is granted.
Errors?
If you received an error message saying your request of making API is abusive, then copy your Project ID in App Name. This should solve this issue.
2.2 Video comments
2.2.1 Identification numbers
To begin with, we create a vector of the videos’ URLs to get the videos’ unique identification numbers (IDs). In a YouTube video URL, the video’s ID is the string of numbers and letters after =. When using vosonSML , we don’t need to manually input video IDs since it has a built-in function to extract IDs from the URLs. You only need to create a vector of URLs.
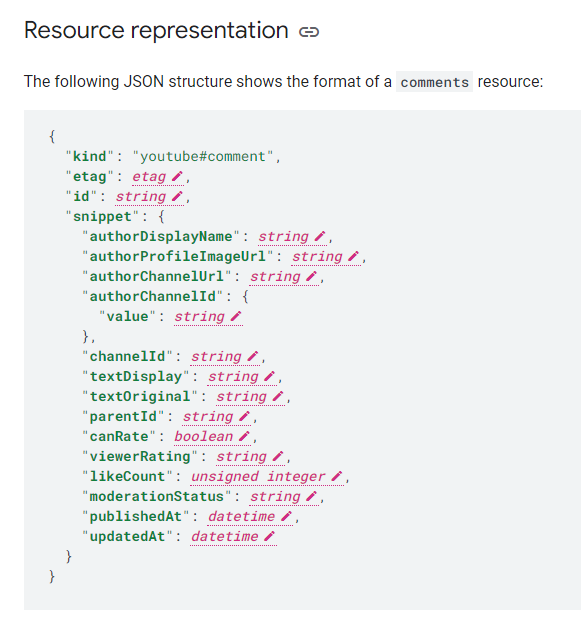
What information about video comments can we retrieve from YouTube’s API? We can find it out from the API’s documentation. The screenshot was taken from the reference page for “Comments”. The terms on the left side of the colons and in green, such as “kind,” “etag,” “id,” and “snippet,” and so on, are the variables we can request from the API.
You can also see that more information is included within some parts, such as “authorDisplayName” in “snippet.”. This is a typical nested or tree structure of raw scraped data. In R, this kind of data will be presented as listed data and need further wrangling.
No worries for now since most of the functions that we use today automatically unnest the listed data. In this case, we will have a nice dataframe to work with. The unnested variable, such as “authorDisplayName” in “snippet,” will be shown as “snippet.authorDisplayName.”
Fig 2. API resource representation of YouTube comments
You can further find the codebook explaining these variables in the following “Properties” table on that reference page. For example, “id” is a string variable, indicating “the ID that YouTube uses to uniquely identify the comment.”
Fig 3. API resource properties of YouTube comments
# codes for scrapping; hold your horses. comments.df <- YT_Auth %>%# this is the credential we have created with APICollect(videoIDs.url,maxComments =500, # for teaching purposes, I set it as 500. writeToFile = T # If TRUE, this collection of comment data will be saved to your work directory as an ".rds" file. )
Tip
You can use the readRDS function to read in the “.rds” file. For example:
Previously, we used load() to read in an RData file. Both Rdata and Rds are R objects that you save for later use. We use RData if we want to save one or multiple objects in one data file. However, Rds is used to save a single object. For example:
The comments.df data set is very network-y, showing the interaction of YouTube users about a video. We will use the YouTube comment data to demonstrate the forthcoming R sessions of social network analysis (and text-as-data analysis). In today’s work, we will stick with the scraping task.
2.3 Find a list of videos through keywords or hashtags
Similarly, if you want to study a YouTube comment network for videos sharing a topic, you may first collect a list of videos through keywords or hashtags. In our example, we search videos with “TidyTuesday” in their descriptions using yt_search. A similar function would be yt_topic_search.
# codes for scrapping; hold your horses. rtuesday0<-tuber::yt_search("TidyTuesday"# published_after ="2016-02-01T00:00:00Z" # you can specify the time window )rtuesday1<-yt_search("TidyTuesday -declutter|house|housecleaning|room|bedroom|bathroom") # remove the "tidy" videos that are about decluttering or house cleaningrtuesday2<-yt_search("TidyTuesday, data") # TidyTuesday & data
We use rtuesday1 data as it excluded those videos about house cleaning.
In real project, defining keywords depends on your research topic. If the keywords are generic, such as “politics”, you will get a huge list of unwanted videos. In our case, keywords and hashtags turn out to be similar since the term “tidytuesday” is specific. See the list of videos for “#tidytuesday”, which has 470 videos from 72 channels. These statistics are close to our rtuesday1 data. 😆✌️
Fig. 4 “#tidytuesday” videos on YouTube
2.4 Channels
Continue working on the rtuesday1 data; let’s then explore which channel has the most videos of TidyTuesday.
rtuesday_channel<-rtuesday1 %>%group_by(channelId) %>%summarise(channel_counts=n()) %>%# the counts of TidyTuesday videos each channel hasarrange(desc(channel_counts)) # order by the highest to the lowestrtuesday_channel
Then, we can get the channel statistics using get_channel_stats. Here, since we want to extract the statistics of all five channels, we can write a function that applies to each channel simultaneously. Again, check out the variables we may obtain from the channel reference page in the API document.
# codes for scrapping; hold your horses. top5_rtuesday_channel_id<- top5_rtuesday_channel$channelIdget_all_channel_stats <-function(channelId) { tuber::get_channel_stats(channel_id = channelId) %>%# returns a listas.data.frame() %>%# convert list to dataframerename(channelId=id) } attr_Top5_rtuesday_channel<-map_df(.x = top5_rtuesday_channel_id, .f = get_all_channel_stats)
You may notice that the get_channel_stats function only fetches the variables from the parts of “kind,” “etag,” “id,” “snippet,” and “statistics.” This is the downside of using the off-the-shelf packages. To obtain additional information, you may want to modify this function by working on its source code or build your own API app.
2.5 Video statistics
The earlier comments.df presents statistics at the comment level. You may want to know further the video-level information, such as how many views and likes of this video. In this case, we can use the get_all_channel_video_stats function from the tuber package to obtain the statistics on all the videos in a user’s channel.
Another function, get_stats, does a similar task of extracting video statistics. However, it requires a list of video IDs and does not return the video creation time. So, I prefer to use get_all_channel_video_stats.
# codes for scrapping; hold your horses. nren_all_channel_video_stats<-tuber::get_all_channel_video_stats(channel_id = top5_rtuesday_channel_id[1])drob_all_channel_video_stats<-tuber::get_all_channel_video_stats(channel_id = top5_rtuesday_channel_id[2])
I have the above codes to take one channel’s video statistics at a time. It is fine for two or five channels. But what if we have many more? In that case, consider writing functions with apply families or looping to conduct repeated coding tasks.
Activity
Can you find the information on the corresponding variables from the API documentation?
2.6 Collecting a playlist
If your study is on a playlist of videos, we need to get each video’s IDs first to obtain its comments data using the above codes.
To do so, manually copying and pasting each video URL is not desired. Instead, we can automate the extraction of video IDs from a playlist using tuber and stringr. The following chunks show this automation using the TidyTuesday playlist of David.
drob_playlist_id <- stringr::str_split(string ="https://www.youtube.com/playlist?list=PL19ev-r1GBwkuyiwnxoHTRC8TTqP8OEi8", # the TidyTuesday playlist of Davidpattern ="=", n =2,simplify =TRUE)[ , 2]
With this list of video IDs, we can further extract their comments, as we’ve worked on earlier. Meanwhile, we can also retrieve the statistics about this playlist, such as its description, created time, and more. See the variables of playlists we can obtain from the YouTube API.
Fig 5. API resource representation of YouTube playlists
We can use get_playlist_items to retrieve playlist information and specify in which part, such as “snippet,” “status,” “conentDetails,” the information we want to obtain.
# codes for scrapping; hold your horses. drob_playlist_contentDetails<- tuber::get_playlist_items(filter =c(playlist_id = drob_playlist_id),part ="contentDetails", # specify the partmax_results = n_video_playlist,simplify =TRUE) #return a dataframe instead of a list. glimpse(drob_playlist_contentDetails)
# codes for scrapping; hold your horses. drob_playlist_snippet<- tuber::get_playlist_items(filter =c(playlist_id = drob_playlist_id),part ="snippet",# set this to the number of videosmax_results = n_video_playlist,simplify = F) #
Note
When getting the snippet information of the videos using the above codes specifying “simplify=T”, an error message appears. This error message was about the failure to convert the list to a dataframe.
Therefore, I specified simplify = F in the above chunk, which returns to a complicated nested list. Converting this list at such a complexity level to a dataframe is beyond this class’s scope. So I will leave it here for now. You may want to give it a try.
# see the complexity of this list#drob_playlist_snippet[["items"]][[1]][["snippet"]]$description